


















同じDBアクセスや同じ計算を、気づかないうちに何度も何度も回してませんか?そのせいで「ページ表示が遅い」「APIが詰まる」「サーバーのCPUがずっと高い」みたいな症状が出がちです。しかも厄介なのが、SQLやロジック自体は正しくても、回数が多いだけで遅くなるところなんですよね。
そこで登場するのが、アプリ内ローカルキャッシュの Caffeine です。ざっくり言うと「よく使う結果をアプリのメモリに置いておいて、次から秒速で取り出す」仕組みです。まずは“アプリの中だけ”で完結するので、Redisみたいな別サーバーをいきなり立てなくても、手軽にスピードアップを狙えます(ただし再起動で消える、複数台だとズレる、みたいな注意もあります)。
この記事では、Caffeineを 最短で1回動かすところから始めて、Cache/Loading/Asyncの使い分け、設定の3点セット(容量・期限・更新)、キー設計と同時アクセスのコツ、そしてSpring Bootの @Cacheable 設定まで、一気に迷子にならない形で整理します。今日から「ムダなDBアクセス」を減らしていきましょう。
ローカルキャッシュって何?まずは図でつかむ
ローカルキャッシュは、めちゃくちゃ雑に言うと「よく使う答えを、アプリのメモリに一時保存しておく仕組み」です。毎回DB(買い物)に行くんじゃなくて、いったん冷蔵庫(メモリ)に入れておいて、次からはサッと取り出す感じです。速いのは当たり前ですよね。
「冷蔵庫(メモリ)に置く」イメージで理解する
なので「同じuserIdで同じプロフィールを何回も取る」みたいな場面は、キャッシュが超効きます。
図:1台構成(基本の勝ちパターン)
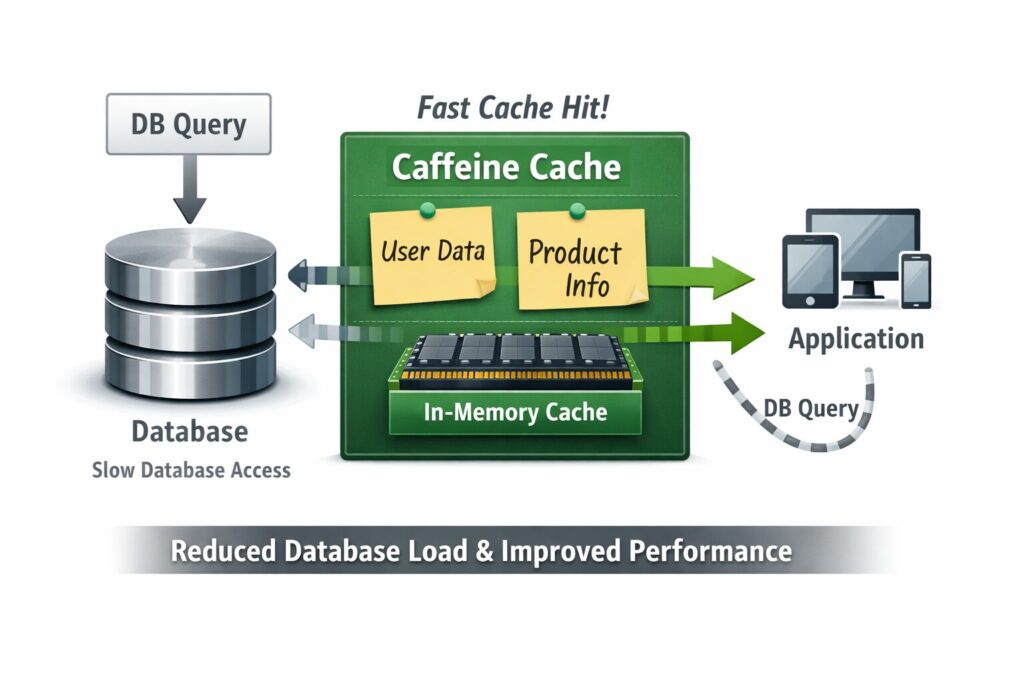
ポイントは、2回目以降の“取りに行く時間”が消えることです。
1台なら速い/複数台だとバラバラ問題
ただしローカルキャッシュは「そのアプリのメモリの中だけ」です。つまり、サーバーが複数台あると話が変わります。
図:複数台構成(値がズレるあるある)
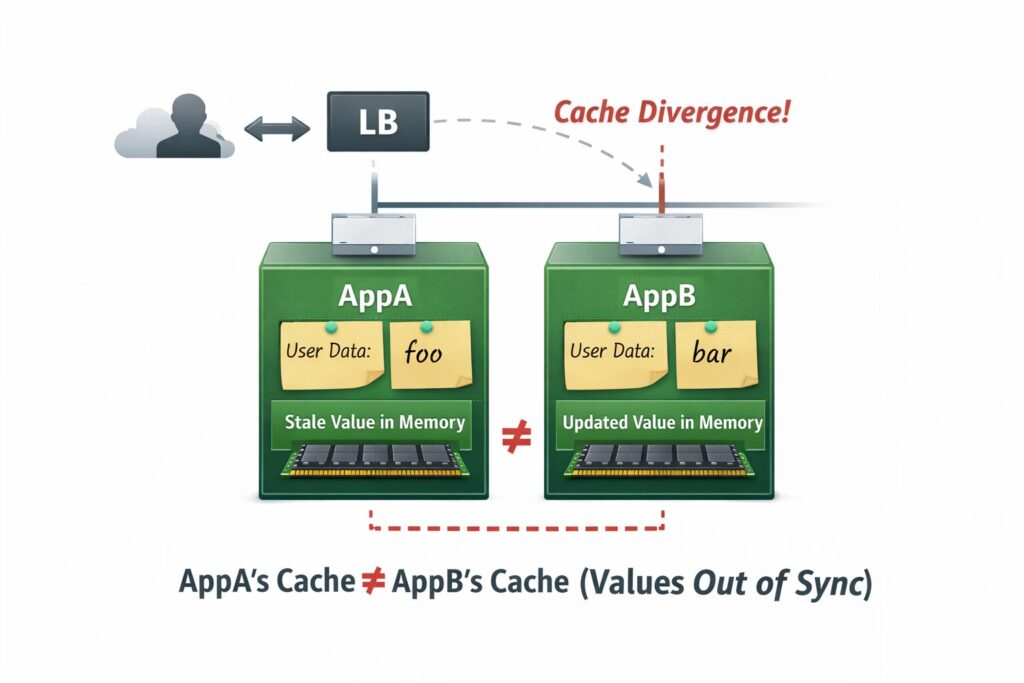
これが「複数台だとバラバラ問題」です。さらに言うと、サーバー再起動したらキャッシュは全部消えます。ローカルなので当然ですね。
なので結論としてはこうです。
どんな処理が“キャッシュ向き”?
キャッシュが向いてるのは、だいたいこのタイプです。
逆に、向いてないのはこんな感じです。
ここまでで「ローカルキャッシュ=冷蔵庫」「1台は強いけど複数台はズレる」「向き不向きがある」まで掴めたらOKです。
次の章で、難しい話は後回しにして、Caffeineを1回動かして“速くなる感”を先に取りにいきます。
最短で動く:素のJavaでCaffeineを1回動かす
難しい理屈の前に、まず“動く成功体験”いきましょう。やることは超シンプルで、Cacheを作る → get(key, loader)で取るだけです。
いちばん小さい例(Cache+get(key, loader))
まず「やってはいけない例」。毎回DB(や重い計算)に行くやつです。
String loadFromDb(String userId) {
// 毎回重い処理(DBアクセス想定)
System.out.println("[DB] load " + userId);
return "profile-" + userId;
}
// 2回呼ぶと2回DBへ…
loadFromDb("u1");
loadFromDb("u1");
次にCaffeine版。同じキーなら2回呼んでも1回しか作られないのがポイントです。
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
public class Main {
public static void main(String[] args) {
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(10_000) // まずはこれだけでOK
.build();
String v1 = cache.get("u1", key -> {
System.out.println("[LOAD] " + key);
// ここがDBアクセス/重い計算の置き場所
return "profile-" + key;
});
String v2 = cache.get("u1", key -> {
System.out.println("[LOAD] " + key);
return "profile-" + key;
});
System.out.println(v1);
System.out.println(v2);
}
}
期待するログはこんな感じです(LOADが1回だけ):
[LOAD] u1
profile-u1
profile-u1
「同じキーなら1回だけ計算される」安心ポイント
この cache.get(key, loader) が偉いところは、同じキーに対して“作る処理”をまとめてくれる点です。つまり「同じuserIdが同時に来て、全員がDBを叩いて地獄」みたいな事故を減らせます(同時アクセスの話は後の章でもう少し触れますね)。
まず付ける設定はmaximumSizeだけでOK
最初に悩むと止まるので、設定はこれで十分です。
期限(expire)や更新(refresh)は、動かして効果が見えてからでOKです。まずは「DBに行く回数が減った」ことをログで確認しちゃいましょう。
3つの型をやさしく整理(Cache/LoadingCache/AsyncLoadingCache)
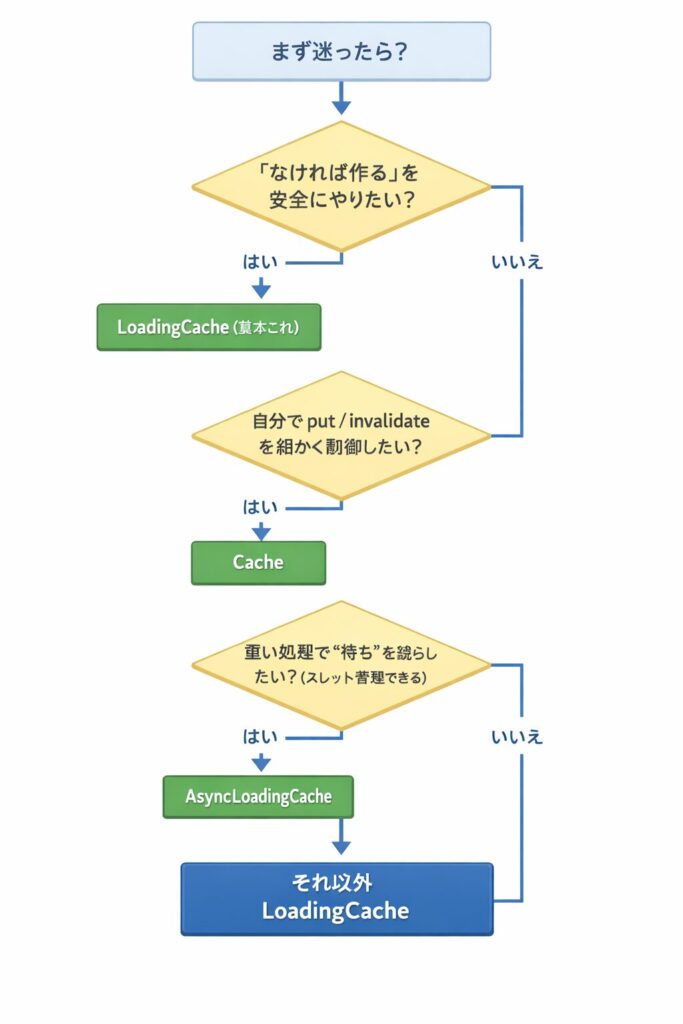
Caffeineで迷う一番の原因は「型が3つある」ことです。覚え方は固定でOKです。
- 自分で入れる
- 足りない時に自動で作る
- 非同期で作る
これだけです。
Cache:手動で入れる・取る(超シンプル)
いちばん素朴なやつです。getIfPresentで取り、なければ自分でDBへ行って、putで入れます。
「どのタイミングで入れるか」を自分で決めたい時に向きます。反面、書き方をミスると「結局毎回DB」になりやすいです。
LoadingCache:足りない時に自動で作る(楽で安全)
「なければ作る」をキャッシュ側に任せます。つまり get(key) するだけで、裏でloaderが呼ばれます。
さっきの章の cache.get(key, loader) を“いつも使う版”みたいなイメージです。迷ったら基本これが安定です。
AsyncLoadingCache:待ち時間を減らす(重い処理向け)
「作る処理」を別スレッドで走らせて、呼び出し側の待ちを減らすための型です。結果は CompletableFuture みたいな“あとで取れる箱”で返ってきます。
ただしここ、勘違いしがちポイントです。
Async=速い魔法ではないです。DBが遅いならDBは遅いままです。できるのは主にこれです。
「重い処理 × 同時アクセスが多い」なら強いですが、スレッドプール設計を雑にすると逆に詰まります。
迷った時の選び方(判断フローチャート)
※非同期の待ち時間や詰まりを見たい時(無料の組み合わせ):
設定は「3点セット」で覚える(容量・期限・更新)
Caffeineって設定が多く見えてビビりがちですが、覚える順番を固定すると一気に楽になります。合言葉はこれです。
容量:maximumSizeの決め方(怖いメモリを守る)
まずは小さく始めるが正解です。最大の事故は「キャッシュが増えすぎてメモリ不足」です。
目安は雑でOKなので、こう考えると止まりません。
※メモリの安全確認(無料):heap dump / Eclipse MAT
※もっと強力に見る(有料):YourKit / JProfiler(数万円〜) あたりの価格帯を検討枠に置く感じです。
期限:expireAfterWrite vs expireAfterAccess(具体例で)
更新:refreshAfterWrite(“アクセスされたら更新が走る”)
refreshは「期限が来たら即捨てる」じゃなくて、期限が来た状態でアクセスされた瞬間に“作り直し”が始まるイメージです。
多くのケースで、更新中でも古い値を返しつつ裏で作り直すので、待ち時間を増やしにくいのが良いところです(※動きは型や実装次第なので、後で軽く検証するのが安全です)。
expireとrefreshが混ざる問題を1枚で解決
| やりたいこと | 使うのは? | 起きること |
|---|---|---|
| 古くなったら“捨てる” | expire | 消える → 次のアクセスで作り直し(待つことがある) |
| 古くなる前に“作り直す” | refresh | アクセスをきっかけに更新開始(古い値でつなげることが多い) |
混乱しないコツはこれです。
refreshは「更新のきっかけ」/expireは「強制退場」。
両方使うなら、だいたい refresh<expire(例:refresh 5分、expire 10分)にして、「更新するチャンス」を先に作ると運用が安定しやすいです。
キャッシュ設計で9割決まる:キー・値・例外のコツ
キャッシュって「入れる」より先に、設計で勝負がほぼ決まります。
ここを雑にすると、だいたいこうなります。
「全然当たらない(効かない)」
「メモリが苦しい」
「条件漏れで別ユーザーの結果が混ざってバグる」
なので、キー・値・例外の3点をテンプレ化しちゃいましょう。
キー設計:userIdだけ?条件も入れる?(失敗例つき)
失敗あるあるはこれです。
おすすめの型は3つです。
→ この場合は「同じ条件なら同じキー」になるように、equals/hashCode(=同じか判定するルール)をちゃんと実装するのがコツです。
値が大きい問題:軽くする/持ち方を変える
値がデカいと、キャッシュは一気にメモリ食いになります。対策はこのへんが現実的です。
null・例外をどうする?(方針を決めるテンプレ)
ここは“先に宣言”が大事です。迷うとバグります。
| ケース | 方針テンプレ(おすすめ) |
|---|---|
| データなし(null相当) | 「短い期限でキャッシュする」or「キャッシュしない」を決め打ち |
| 例外(DB落ち/タイムアウト等) | 基本:キャッシュしない(失敗を保存すると復旧後も死にます) |
※キー実装ミスを減らしたい時:
- SpotBugs / Checkstyle(「equals/hashCodeのうっかり」みたいなミスを早めに潰せます)
運用の基本操作セット(消す・更新する・効いてるか見る)
キャッシュは「入れたら終わり」じゃなくて、更新が入った時にどう直すかと、本当に効いてるかが超大事です。ここを手順化しておくと、事故が激減します。
invalidate / invalidateAll(更新・削除の基本)
基本はこれだけ覚えればOKです。
cache.invalidate(key); // 1件
cache.invalidateAll(keys); // 複数件
cache.invalidateAll(); // 全部
置き方のコツはシンプルで、「DB更新が起きる場所」から逆算してinvalidateを置くだけです。
例:ユーザー更新APIが成功したら userId のキャッシュを消す、みたいに「更新イベント→削除」をセットで考えると迷いません。
手動更新(refresh/put)の使いどころ
「消す」以外に「更新する」もあります。ただし使いどころは限定でOKです。
loadingCache.refresh(key); // 裏で更新してね(※型による)
cache.put(key, newValue); // 新しい値があるなら即入れ替え
使いどころの例:
統計(hit率)で“効いてるか”確認する手順
「速くなった気がする」だと危ないので、数字で見ましょう。Caffeineは統計が取れます。
Cache<K, V> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.recordStats()
.build();
// どこかで
var stats = cache.stats();
System.out.println("hitRate=" + stats.hitRate());
System.out.println("evictionCount=" + stats.evictionCount());
おすすめ手順:
- まずキャッシュなしの処理時間を測る(基準)
recordStats()で hit率 と 追い出し回数 を見る- hit率が低いなら「キーがズレてる/期限が短すぎ」疑い
追い出しが多いなら「maximumSizeが小さすぎ」疑い - 1個ずつ直して、また測る(計測→調整→計測)
運用で見える化したい時:
Spring Boot最短手順:@Cacheableで迷わない設定場所
Spring Bootだと迷いポイントは「設定どこ?」ですが、答えはだいたい二択です。①まずは application.yml の spec、足りなくなったら ②Beanで細かく、でOKです。
依存関係(starter-cache+caffeine)
implementation "org.springframework.boot:spring-boot-starter-cache"
implementation "com.github.ben-manes.caffeine:caffeine"
application.ymlのspec例(maximumSize/expire/refresh)
spring:
cache:
type: caffeine
caffeine:
spec: maximumSize=10000,expireAfterWrite=10m
※refreshAfterWrite は CacheLoader(LoadingCache)前提で効くやつなので、@Cacheable だけで「勝手に裏更新」まではしません。必要になったらBeanでLoadingCacheを作る、くらいの理解で大丈夫です。
@Cacheable / @CacheEvict / @CachePut を1画面で整理
| 役割 | 何する? | いつ使う? |
|---|---|---|
@Cacheable | 読む(なければ作る) | 読み取りが多い処理 |
@CachePut | 更新して入れる | 更新後に“新しい値”を即反映したい |
@CacheEvict | 削除する | DB更新したので古いキャッシュを消す |
「DB更新とキャッシュ整合」よくある事故の避け方
事故はだいたいこれです:DBは更新したのにキャッシュが残って古いまま。対策はシンプルで、更新系メソッドに @CacheEvict(or @CachePut)をセットしてください。さらに安全にするなら「更新が成功してから消す(入れる)」を意識です。
おまけで、効いてるか見るなら Actuator+メトリクス出力が便利枠です(“本当に当たってる?”がすぐ分かります)。
Guava Cacheからの乗り換え&ローカル卒業の判断表
置き換え対応表(だいたい同じ、ここが違う)
| Guava | Caffeine | ひとこと |
|---|---|---|
CacheBuilder.newBuilder() | Caffeine.newBuilder() | 入口が違うだけです |
maximumSize / expireAfterWrite | 同名 | ほぼそのまま移せます |
LoadingCache | LoadingCache | これも同名です |
| (弱め) | AsyncLoadingCache | 非同期を使いやすいのが強みです |
いつローカルじゃ足りない?判断表
| 状況 | 結論 |
|---|---|
| 1台構成 | ローカル推しです(速い・簡単) |
| 複数台で“同じ値”を共有したい | Redis等を検討です |
| 常に最新が必須(ズレ厳禁) | 共有キャッシュ or そもそもキャッシュ慎重にです |
複数台ならRedis等(ハイブリッド案の考え方)
現実解は ローカル(短い期限)+Redis(共有) が多いです。まずローカルで速くして、共有が必要な所だけRedisに寄せると、移行も事故も減らせます。
商品カテゴリとしては「分散キャッシュ=Redis(OSS/マネージド)」「監視=Grafana」あたりが定番枠です。
まとめ:今日やるチェックリスト+おすすめテンプレ(CTA)
最後に「今日やる」だけに絞ったチェックリストです。これだけやれば、だいたい最初の改善は出ます。
まず1つだけテンプレ(最小構成)
Spring BootならこれをコピペでOKです。
spring:
cache:
type: caffeine
caffeine:
spec: maximumSize=10000,expireAfterWrite=10m
もし「最小サンプルコード」や「チートシートPDF」みたいな配布物を作る想定なら、この記事のテンプレ(spec例・キー例・invalidate配置例)をそのまままとめるのが一番ラクです。
まずは1か所だけキャッシュして、DBアクセス回数が減る快感を取りにいきましょう。
よくある質問
- QCaffeineって、結局なにが速くなるんですか?
- A
同じ結果を何度も作らないので速くなります。DBアクセス・外部API呼び出し・重い計算を、2回目以降はメモリからサッと返せるのが効きます。
- Qローカルキャッシュって、再起動したらどうなりますか?
- A
全部消えます。アプリのメモリに置いてるだけなので、再起動・デプロイで初期化されます。「消えても困らない」「すぐ作り直せる」前提で使うのが安全です。
- QmaximumSize はいくつにすればいいですか?
- A
最初は 小さめでOKです。目安は「よく出るキーが何件あるか」から決めて、
recordStats()の hit率 とメモリ使用量を見て調整がラクです。いきなり大きくするとメモリ不足で事故りやすいです。
- QexpireAfterWrite と expireAfterAccess、どっちを使えばいいですか?
- A
迷ったら expireAfterWrite が無難です。
- QrefreshAfterWrite は expire と何が違うんですか?
- A
expireは捨てる、refreshは作り直すです。
- Q同時アクセスが多いと、同じキーでDBが何回も叩かれませんか?
- A
cache.get(key, loader)/ LoadingCache なら、同じキーの作成をまとめやすいです(いわゆる「同時に押し寄せて全員DB」事故を減らせます)。ただし、設計や実装が雑だと起きるので、重要キーは負荷テストで確認が安心です。
- Qnull(データなし)や例外はキャッシュしていいんですか?
- A
方針を決め打ちがおすすめです。
- QSpringの @Cacheable でキーってどうなりますか?
- A
基本は「メソッド引数から自動でキー」が作られます。
ただし落とし穴があって、引数が複雑だったり、条件(言語/権限/フィルタ)をキーに入れてないと、違う結果が同じキー扱いになってバグります。必要ならkey = "..."
で明示が安全です。
- QDB更新したのに、古いキャッシュが返る事故を防ぐには?
- A
更新処理のところで、必ずどれかをやります。
- Q複数台構成(スケールアウト)でもローカルキャッシュでいいですか?
- A
“いい場合”と“ダメな場合”があります。