

















強化学習って、なんだか“むずかしそうな言葉のかたまり”に見えてしまって、最初の一歩が重いですよね。「エージェント?」「報酬?」みたいな専門用語がいきなり出てくると、ちょっと身構えてしまう気持ち、すごくよくわかります。
でも実は、強化学習の本質って 「ゲームで遊びながらコツをつかむ」 みたいな、とってもシンプルなしくみなんです。そこでこの記事では、いきなり数式に飛び込むのではなく、まずは 紙に描いた簡単な迷路 を使って、“手で触れるように”理解していただくスタイルで進めます。
やることはめちゃくちゃ軽くて、「ゴールに向かって進むだけ」。それなのに、強化学習の大事な考え方——エージェント・環境・報酬・Q値——がスッと入ってくるように工夫しています。
そしてゴールは、「Q学習ってこういうことか!」と気持ちよく理解して、さらに 自分でコードをいじって遊べるところまで到達すること です。記事の後半では、ミニマルなPythonコードをていねいに分解し、環境構築の不安もゼロにできるように、Windows/Mac それぞれの手順も用意しています。
「強化学習をちゃんと学びたいけど、どこから始めればいいの?」
そんな方でも、この記事を読み終わる頃には “自分の手で動かせる強化学習” がきっと身につくはずです。ゆるっと楽しみながら、一緒に迷路からはじめてみませんか?



強化学習は「ゲームで遊んで学ぶ」しくみ
強化学習をひとことで言うと、「やってみて、うまくいったらごほうびをもらえるゲーム」 みたいなものです。むずかしい理論より、まずはこの感覚をつかんでいただくほうが理解がグッと早くなります。ここでは、紙に描いた迷路を使って、そのイメージをつかんでいきますね。
「エージェント」「環境」「報酬」を紙の迷路で理解
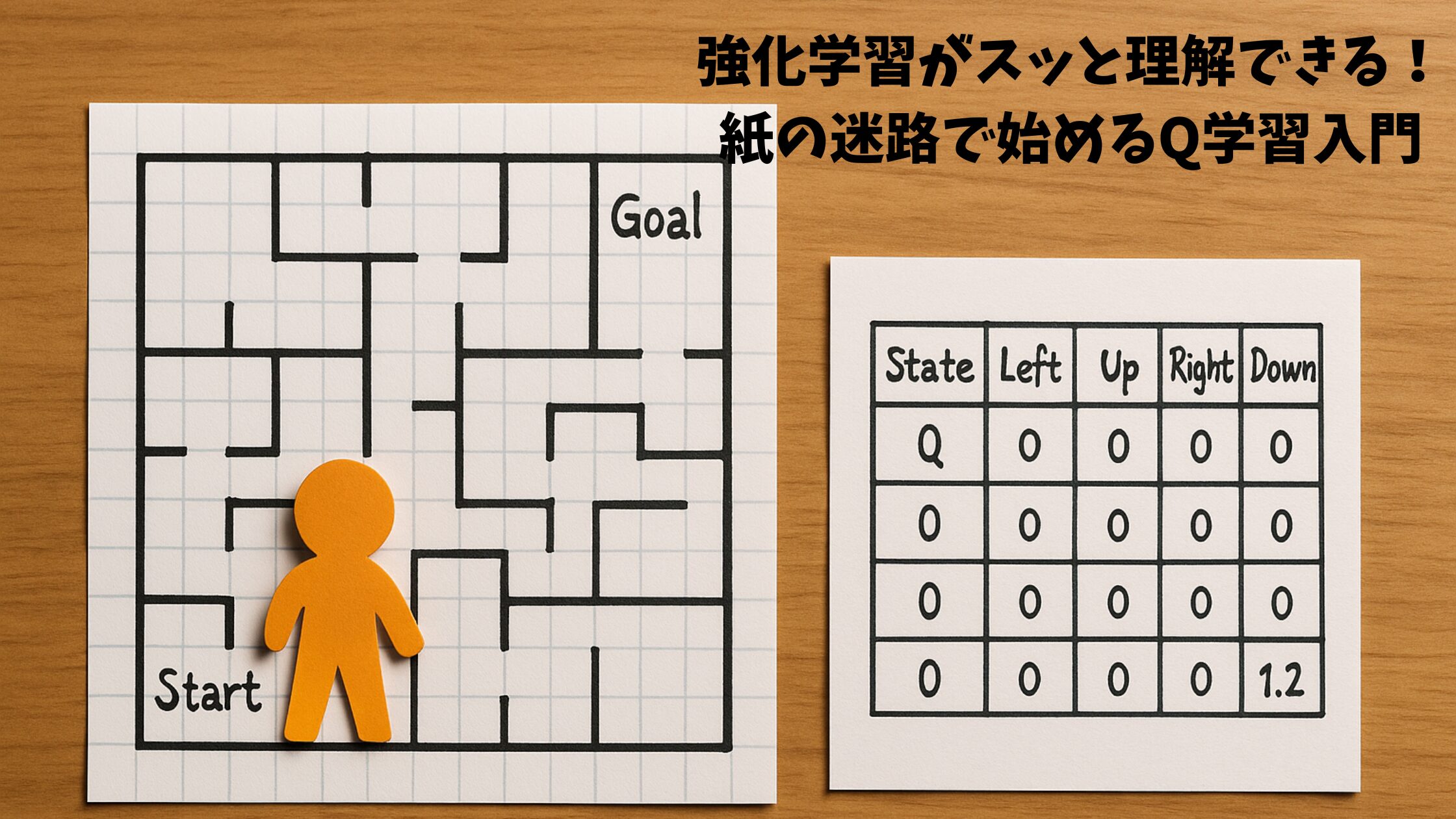
紙に迷路を描いて、スタートからゴールまで進むゲームを想像してください。ここでは、プレイヤー(エージェント)が一歩ずつ動き、周りの状況(環境)を見ながら「上・下・左・右」のどれかを選びます。ゴールについたら「やった!+1のごほうび!」のように、うれしい点数(報酬)がもらえます。

強化学習がしていることは、この遊びとほぼ同じです。
「エージェントが行動して → 環境から結果と報酬が返ってくる」
この繰り返しだけで、だんだん“うまい歩き方”を学んでいくのが強化学習なんです。なんだかゲームっぽいですよね。
「Q値=行動の良さノート」を日常の例で説明
Q学習でよく出てくる Q値(キューち) は、一言でいうと
「この場所で、この行動をしたら、どれくらいいいことがありそうか?」
を記録しておくノートみたいなものです。

たとえば、あなたが「雨の日にどの道を通ると濡れにくいか」をメモしていくとします。
こんなふうに、「行動の良さ」を数字でメモしていく感覚がそのままQ値です。
紙迷路でも同じで、「このマスで右に進んだら良さそうだぞ!」とわかったら、その“右に進む”という行動のQ値が上がります。逆に、ぶつかったり、遠回りになったらQ値は下がります。
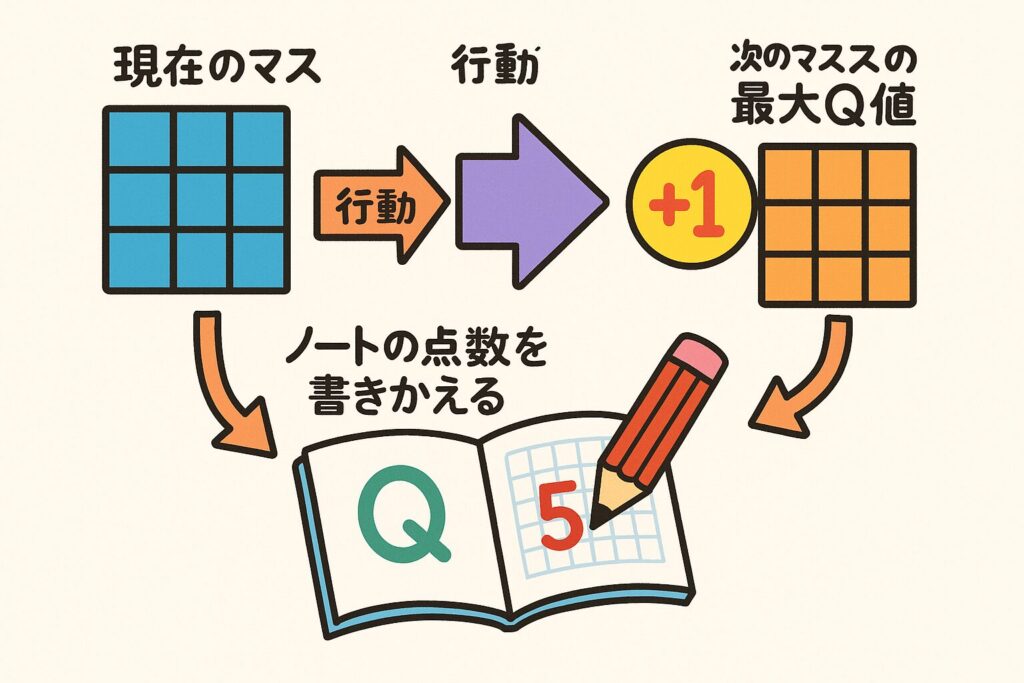
そして、学習するときは
「今日やった行動の結果を見て、ノートの点数をちょっと書きかえる」
というイメージだけ持っておけば大丈夫です。数式はあとでゆっくり理解すればOKで、まずはこの“ノートづくり”の感覚がつかめれば強化学習の半分はクリアと言っていいレベルです。
最初に知るべき入門ロードマップ
強化学習って、ネットで調べると専門用語やコードが山ほど出てきて、「どれから手をつけたらいいの…?」と迷いやすいんですよね。そこで、この記事では 最短で迷わず進める4ステップのロードマップ をご紹介します。順番にはちゃんと理由があるので、安心してこの流れに乗っていただければOKです。
- Q学習のしくみを理解する
→ まずは“ごほうびをもらいながら学ぶ”という強化学習の芯の部分をつかむのが大事です。紙の迷路がまさにここ。 - ε-greedy(えぷしろん・ぐりーでぃ)で「探す」と「得する」のバランスを知る
→ 新しい行動を試すか、今知っている良い行動を選ぶか。このバランスを体で理解すると、強化学習の動きが一気にイメージしやすくなります。 - Gymnasium を使って本物の環境で練習する
→ ここから急に世界が広がります。「CartPole」などの定番ゲームを、紙迷路で学んだ考え方そのままで扱えるようになります。 - DQN(ディーキューエヌ)で“深層学習 × 強化学習”へ進む
→ ここまで来ると、ニューラルネットを使う本格的な強化学習にも迷わず入れます。Q学習の理解が土台になるので、つまずきにくいです。
この流れは「理解 → 実験 → 本格環境 → 応用」という自然なステップなので、強化学習の“迷子ルート”を避けたい人にぴったりです。
Q学習を紙の迷路で実装してみる
ここからいよいよ、紙の迷路をそのまま Python に落とし込んで、“動くQ学習” を体験していただきます。といっても、やることはめちゃくちゃシンプルで、「迷路を2Dリストにして、Q値も2Dリストにして、エージェントが歩くだけ」です。コードの行数も少ないので、強化学習が“黒魔術じゃない”ことがすぐにわかるはずです。
まずは、全体像になるミニマルコードをご覧ください。
import random
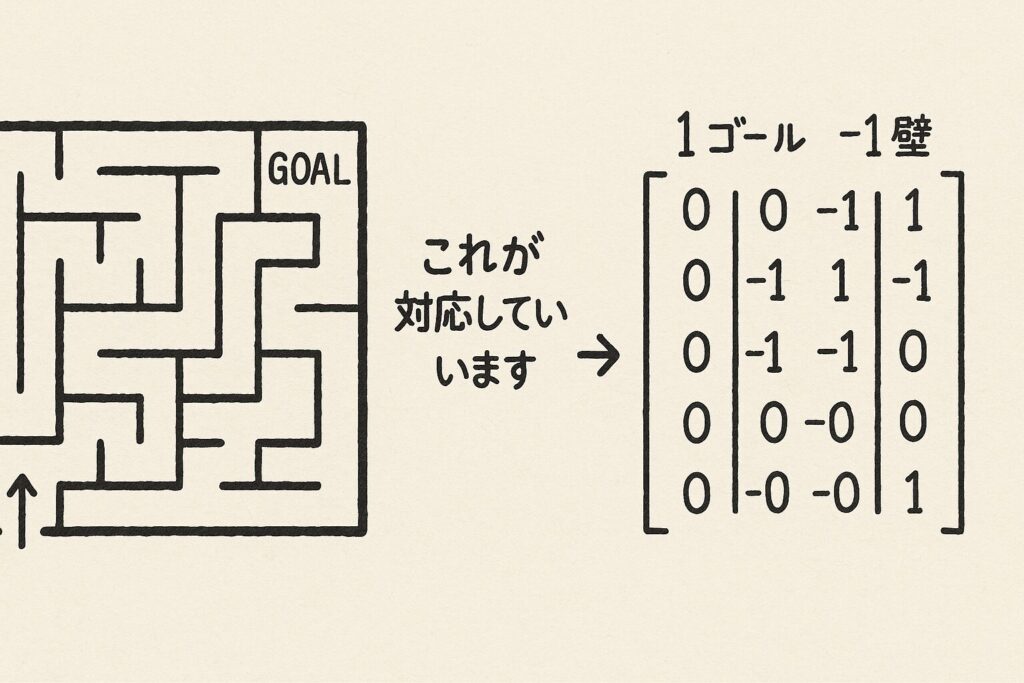
maze = [
[0, 0, 0, 1], # 1がゴール
[0, -1, 0, -1], # -1は壁
[0, 0, 0, 0]
]
# Q値表(行・列・4方向の行動の良さ)
Q = [[[0, 0, 0, 0] for _ in row] for row in maze]
actions = [(0,1), (0,-1), (1,0), (-1,0)] # 右 左 下 上
alpha = 0.2
gamma = 0.9
epsilon = 0.2 # たまに探検
def is_valid(r, c):
return 0 <= r < len(maze) and 0 <= c < len(maze[0]) and maze[r][c] != -1
for episode in range(20):
r, c = 0, 0 # スタート
while maze[r][c] != 1:
if random.random() < epsilon:
a = random.randint(0, 3)
else:
a = Q[r][c].index(max(Q[r][c]))
dr, dc = actions[a]
nr, nc = r + dr, c + dc
if not is_valid(nr, nc):
reward = -0.5
nr, nc = r, c
else:
reward = 1 if maze[nr][nc] == 1 else -0.01
Q[r][c][a] = Q[r][c][a] + alpha * (reward + gamma * max(Q[nr][nc]) - Q[r][c][a])
r, c = nr, nc
print(Q)
1エピソードの流れを1行ずつ理解
ここではコードの“意味”だけを、日常の言葉に置き換えて説明します。
※ここまでで、抽象的な記号が全部“生活の言葉”に変わりました。
ループに入ると、エージェント(あなた)はスタートに立ちます。
if random.random() < epsilon:
a = random.randint(0, 3)
→ ときどき“気まぐれ探検”をします。
else:
a = Q[r][c].index(max(Q[r][c]))
→ それ以外は「今いちばん良さそうな行動」を選びます。
次に、進んだ先が「壁かどうか」をチェックします。壁なら
という、紙迷路と同じ動きになります。
そしていちばん大事な部分がここ↓
Q[r][c][a] = Q[r][c][a] + alpha * (reward + gamma * max(Q[nr][nc]) - Q[r][c][a])
これは難しく見えますが、やっていることはただひとつ。
「今日の行動はどうだった?ノートの点数を少しだけ書きかえよう」
という作業です。
ここが“強化学習らしい”ポイント解説
Q学習のキモは “行動の良さを、経験しながら少しずつ書き換えていく” 点です。
この更新式は「今日のごほうび」だけを見るのではなく、未来でもらえるごほうびの見込み まで考えています。ここが人間の“学習”にすごく近くて、強化学習が面白いところなんです。
さらに、“たまに探検(epsilon)”することもめちゃくちゃ大事です。
良さそうな行動だけを選び続けると、実はもっと良いルートがあるのに気づけないことがあります。なので、ちょっとだけ冒険することで、「もっといい選択肢」を発見できるようになる わけです。
最後に、Q表を print(Q) で見てみると、マスごとに数字が増えているのが確認できます。これがエージェントが「うまく歩けるようになった証拠」です。
自分のPCで動かすための環境構築(Windows/Mac)
ここでは、先ほどのQ学習コードをご自分のPCでそのまま動かせる環境づくりをしていきます。「環境構築って聞くだけで不安…」という方も大丈夫です。やることはほぼ3つだけです。
① Python を用意する → ② 仮想環境をつくる → ③ 必要なライブラリを入れる
この流れさえ守れば必ず動きます。
必要なライブラリと仮想環境の作り方
● 共通:必要なのはこれだけ
- Python 3.10 以上
- インストールするライブラリ:
numpy(計算が速くなる便利ツール)
VSCode や Google Colab を使うのもおすすめですが、ここではローカルで動かす最小手順だけを紹介します。
● Windows の場合
- Python を公式サイトからインストール(“Add to PATH” にチェック)
- コマンドプロンプトで以下を実行
python -m venv rl-env rl-env\Scripts\activate pip install numpy python your_file.pyで実行できます。
● Mac の場合
Mac は複数バージョンのPythonが入りやすいので、python3 を使うのが安心です。
python3 -m venv rl-env
source rl-env/bin/activate
pip install numpy
これで準備完了です。
※ もし Python のバージョン管理が不安な場合は、pyenv や miniconda を使う選択肢もあります(どちらも無料で、後からより高度な環境をつくるときに便利です)。
つまずきやすいエラーと対処例
● “pip: command not found” と出る
→ Python が PATH に入っていない可能性があります。インストールし直すか、pyenv などを利用してください。
● “No module named numpy” と出る
→ 仮想環境が有効化されていないことが多いです。
Windows:rl-env\Scripts\activate
Mac:source rl-env/bin/activate を再実行。
● 権限エラー(Permission denied)
→ Mac の場合、python ではなく python3 を使うと解決することが多いです。
いじって変化を楽しむ:報酬・学習率・行動を変える練習課題
ここからは、Q学習を“見るだけ”ではなく、自分でいじって遊ぶフェーズです。紙迷路のコードはシンプルなので、数字を少し変えるだけでガラッと性格が変わります。小学生の自由研究みたいなノリで、気軽に試してみてください。
● 報酬を変える:ゴール報酬を「1 → 10」にする
コード内の
reward = 1 if maze[nr][nc] == 1 else -0.01
この「1」を 10 にすると、エージェントは“絶対にゴールしたいマン”になります。遠回りしてでもゴールをめざすようになり、Q値の強弱がもっとハッキリ出ます。
● 学習率(alpha)と割引率(gamma)を変える
- alpha を 0.2 → 0.5 にすると、ノートの書きかえが雑になり、学習スピードは上がりますがブレやすくなります。
- gamma を 0.9 → 0.5 にすると、“未来より今のごほうびを重視する派”になります。短期的には動きやすいけど、ゴールに近づきにくくなる場合も。
数字1つで性格が変わるのが、強化学習の面白いところです。
● 行動を増やす・減らす
例えば「その場にとどまる」という行動を追加すると、Q配列を [5つ] にする必要があります。逆に「上方向は封印!」など行動を減らすと、エージェントの選択肢が狭くなるので、ゴールまでの動きが極端に変わったりします。
次の一歩:GymnasiumやCartPoleへ接続する方法
紙の迷路でQ学習の流れがつかめたら、次は本物の強化学習の世界に足を踏み入れてみましょう。といっても、いきなり複雑なコードを書く必要はありません。実は、Gymnasium(ジムナジウム)という無料ライブラリを使えば、紙迷路とほぼ同じ考え方のまま、ブランコの棒を倒さずにバランスを取る「CartPole」などの有名ゲームに挑戦できます。
ポイントは 「全部覚えようとしないで、差分だけ見る」 ことです。
● 紙迷路コードとの“差分だけ”を見るとこうなる
紙迷路では自分で
を書いていましたが、Gymnasium ではこれらを 環境(env)が全部やってくれる んです。
最小のコードはこんな感じです:
import gymnasium as gym
env = gym.make("CartPole-v1")
state, _ = env.reset()
for _ in range(200):
action = env.action_space.sample() # とりあえずランダム行動
next_state, reward, terminated, truncated, _ = env.step(action)
if terminated or truncated:
break
紙迷路版と比べて変わったところは
- 状態が
stateとして自動で返ってくる env.step(action)が「次の状態+報酬+終わりかどうか」を全部返す
これだけです。Q学習の仕組み自体は同じなので、更新式もそのまま流用できます。
stable-baselines3 を使うと「学習ループを書かなくていい」
もう一歩進みたい方は、stable-baselines3 という無料ライブラリがおすすめです。こちらは「学習のめんどうな部分」を全部まとめてやってくれるので、
from stable_baselines3 import DQN
model = DQN("MlpPolicy", env, verbose=1)
model.learn(10000)
みたいに超短いコードで、本格的なDQNが動きます。
紙迷路で“しくみ”がわかっている方なら、Gymnasium でも CartPole でも、実はやっていることは同じ。
「状態を受け取る → 行動する → 報酬が返る」
この流れさえつかんでいれば、次のステップはもう怖くありません。
よくある質問
- Q強化学習って、どれくらいむずかしいんですか?
- A
数式だけ見るとむずかしそうに見えますが、しくみ自体は「ゲームで遊びながら学ぶ」だけなので、実はめちゃくちゃシンプルです。紙の迷路から始めれば安心です。
- Qプログラミング初心者でもQ学習できますか?
- A
できます!この記事のコードは“最小サイズ”なので、Pythonの基本文法が少しわかれば動かせます。むしろ初心者の方ほど紙迷路での理解が効きます。
- Q迷路のサイズを大きくしたらどうなりますか?
- A
Q表が大きくなるだけで、考え方はまったく同じです。ただし学習に時間がかかるので、最初は小さめの迷路のほうが結果がわかりやすいです。
- QQ値って0から始める理由はありますか?
- A
はい。「まだ何も知らない状態だから全部同じ」とするためです。ゼロスタートのおかげで、行動の良さが“純粋に経験で決まる”ようになります。
- Qpsilon(探検の割合)はどれくらいがいいんですか?
- A
最初は 0.1〜0.3 が扱いやすいです。大きいほど冒険しますが、学習が安定しにくくなります。小さいと冒険しなさすぎて新しい道を覚えられません。
- QWindows と Mac で動き方は変わりますか?
- A
いえ、Python が動けばほぼ同じです。仮想環境の作り方だけ少し違いますが、コードそのものは全OSでまったく同じように動きます。
- Qうまく学習しないときは何を見直せばいいですか?
- A
よくある原因は
あたりです。まずは数字を少しゆるめにすると改善しやすいです。
- QCartPole に挑戦するのは早いですか?
- A
この記事レベルの紙迷路が理解できていれば、むしろちょうどいいタイミングです。コードの差分だけで理解できるので、恐れずチャレンジしてOKです。
- Qstable-baselines3 を使うと、学習内容が理解できなくなりませんか?
- A
心配いりません。中の仕組みはQ学習やDQNを丁寧に実装しただけなので、紙迷路で基礎があると“ブラックボックス感”がかなり減ります。
- Q自分で作ったゲーム(迷路以外)でも強化学習できますか?
- A
できます!「状態を返す」「行動を受け取る」「報酬を返す」の3つがそろえば、なんでも強化学習の舞台にできます。簡単なボードゲームから始める人も多いです。