


















「強化学習ってむずかしそう…」「数式が出てきた瞬間に心が折れる…」
そんな気持ち、めちゃくちゃよく分かります。名前だけ聞くとすごい専門技術に見えますし、ネットで調べても急に数学の話が登場して“そっと閉じる…”みたいなことになりがちですよね。
でもご安心ください。本記事では 数式ゼロ・Python中心・日常のたとえ多め で、強化学習の流れをスーッと理解できるようにまとめています。小学生でも読めるレベルで説明しているので、「なんとなく全体像は分かったかも!」という状態までしっかり案内いたします。
さらに、この記事の後半では Q学習が30行くらいで動くミニコード も紹介します。コピペで実行できるので、「とりあえず動かしてみたい」という方でも大丈夫です。環境構築のつまずきポイントも先回りで解決するので、初学者の方でも安心して読み進められます。
強化学習は“試して学ぶ”という、とてもシンプルで直感的な考え方です。この記事を読み終えるころには、「あ、意外といけるかも!」と思えるはずです。それでは、一緒にゆっくり進めていきましょう。
強化学習とは?日常の例で「試して学ぶ仕組み」を理解する
強化学習って聞くと「ロボットが勝手に学ぶすごい技術!」みたいなイメージがあるかもしれませんが、実はすっごく身近な考え方なんです。たとえば、RPGでレベル上げするときって、敵を倒したりクエストをこなしたりして「どこで経験値が多くもらえるか」自然と学びますよね。ポケモンでも「この技が効く!」とか「このタイプは危ない!」みたいに、戦っているうちに分かってきます。まさにあれが強化学習のノリなんです。
強化学習はざっくり言うと 「行動をして、ごほうびが増えるように学んでいく仕組み」 です。たくさん試して、うまくいった行動を少しずつ覚えていくので、人間の“経験で学ぶ”感覚にかなり近いんですよ。
教師あり・教師なし・強化学習の違いを図で整理
強化学習を理解する前に、よく聞く3つの学習タイプをざっくりイメージしておくとめちゃ楽です。

専門用語をやさしく定義(状態・行動・報酬)
強化学習ではいくつか専門用語が出てきますが、ここでは小学生向けにサクッと説明しますね。
この3つさえ分かっていれば、強化学習の9割は理解できていると言ってもいいくらい大事です。次の章では、この「状態・行動・報酬」をつかって、エージェント(学ぶキャラ)がどう成長していくのかを見ていきますね。
Q学習を数式なしで理解する:表で学ぶエージェントの成長
Q学習は、強化学習の中でも“いちばん最初に触ると理解しやすいタイプ”です。理由はシンプルで、数式より「表」を使って学ぶからなんです。むずかしい計算をしなくても、「あ〜、このマスでは右に行ったほうが得なんだな」みたいな感じで理解できます。
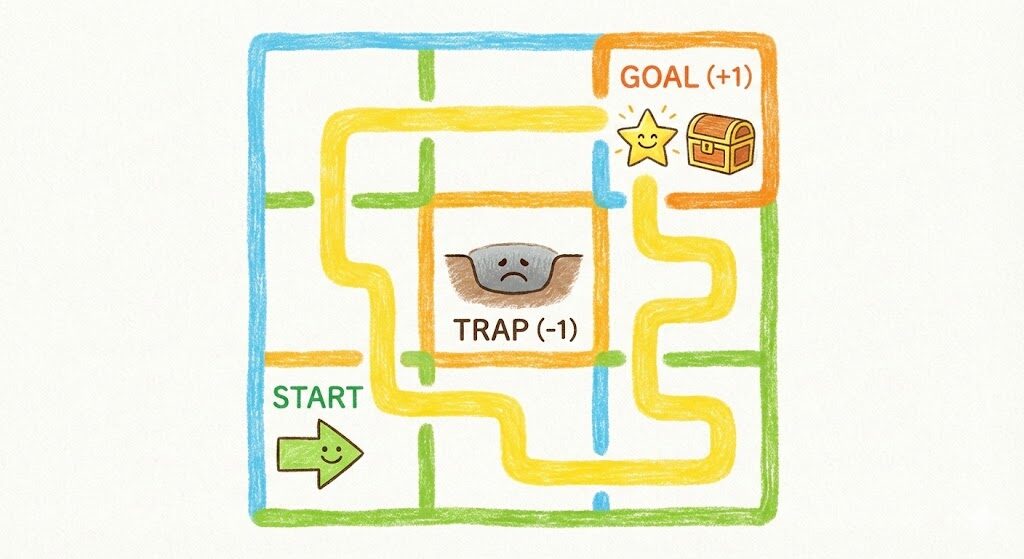
まずイメージしてほしいのは、小さな迷路ゲームです。スタート地点からゴールに向かって動くキャラ(エージェント)がいて、毎回「上・下・左・右」のどれかを選んで進みます。でも最初は、どの方向が正しいかなんて分かりません。だから、とりあえず適当に動いてみるところから始まります。これが“試行錯誤”ですね。
迷路ゲームの例で「報酬最大化」を体験
エージェントは、うまくゴールに近づくと**報酬(ごほうび)**をもらえます。逆にワナに落ちるとマイナスのポイント。これを何度もくり返すうちに「あ、この道のほうが得だ!」と少しずつ覚えていきます。
Qテーブルとは?必要なものと学習の流れ
Q学習の主役が Qテーブル です。これは「この場所(状態)で、この行動をすると、どれぐらい良さそうか?」を数字でメモしていく“成績表”みたいなものです。
例:Qテーブル
| 状態 | 上 | 下 | 左 | 右 |
|---|---|---|---|---|
| S1 | 0 | 0 | 0 | 0 |
| S2 | 0 | 0 | 0 | 0 |
| … | … | … | … | … |
最初は全部 0 のスカスカ表ですが、エージェントが行動するたびに、成功すれば数字が少しプラスに、失敗すればマイナス方向へ修正されていきます。
流れとしてはこんな感じです👇
- いまの状態を確認
- 行動をひとつ選ぶ
- 報酬をもらう
- Qテーブルのその行動欄をちょっと更新する
- これを何度もくり返す
この“ちょっと更新する”の積み重ねによって、エージェントはだんだん賢くなるんです。次の章では、いよいよこのQ学習を Python で実際に動かしますね!
PythonでQ学習を動かす:環境構築〜30行サンプルコード
「Q学習って結局コードどう書くの?」という疑問、ここで一気に解消いたします!
この章は“必ず動く状態を作ること”を最優先にしています。Python が初めての方でも、順番どおりに進めればゴールまでたどり着けるようにしていますのでご安心ください。
Python・numpy・gymnasium の準備とエラー対処
▼ まずは Python を用意
Python のバージョンは 3.9〜3.11 あたりなら何でもOKです。
インストールが面倒なら Google Colab(無料) を使う方法もあります。ノートPC(5万円〜)でも十分動きます。
▼ 必要なライブラリ
ターミナル(またはColab)で以下を実行してください👇
pip install numpy gymnasium▼ よくあるエラー
❌ gym と gymnasium のバージョン衝突
ModuleNotFoundError: No module named 'gym'→ 解決策:
pip uninstall gym
pip install gymnasium❌ 依存パッケージが古い場合
pip install --upgrade pip setuptoolsで一度更新すると直りやすいです。
コピペで動くQ学習サンプル(全行解説つき)
以下のコードは 30行ちょいの最小Q学習 です。
環境として「FrozenLake(氷の上を歩いてゴールを目指すミニゲーム)」を使います。
import numpy as np
import gymnasium as gym
env = gym.make("FrozenLake-v1", is_slippery=False)
q = np.zeros((env.observation_space.n, env.action_space.n))
episodes = 500
lr = 0.1
gamma = 0.99
epsilon = 0.1
for _ in range(episodes):
s, _ = env.reset()
done = False
while not done:
if np.random.rand() < epsilon:
a = env.action_space.sample()
else:
a = np.argmax(q[s])
ns, r, done, _, _ = env.step(a)
q[s, a] += lr * (r + gamma * np.max(q[ns]) - q[s, a])
s = ns
print("学習後のQテーブル:")
print(q)▼ コードのざっくり解説
少しアレンジして遊べる課題
学習が終わったら、次のように変更するともっと楽しく学べます!
DQNへのステップアップ:なぜ深層学習が必要になるのか
Q学習はとても分かりやすい仕組みですが、じつは“弱点”もあります。それは 「世界が大きくなると、表(Qテーブル)が巨大になってしまう」 ということです。
たとえば、迷路が 3×3 から 30×30 に大きくなるだけで、状態の数は100倍以上。さらにロボットの画像やゲーム画面を「状態」として扱おうとすると、もう表ではまったく管理できません。画像1枚に何万ものピクセルがありますからね…。
そこで登場するのが DQN(Deep Q-Network) です。これは、Qテーブルの代わりに ニューラルネットを使って「Q値を予測する」 方法なんです。つまり、表の代わりに“頭脳そのもの”を作るイメージです。
▼ DQN の全体イメージ(図プロンプト)
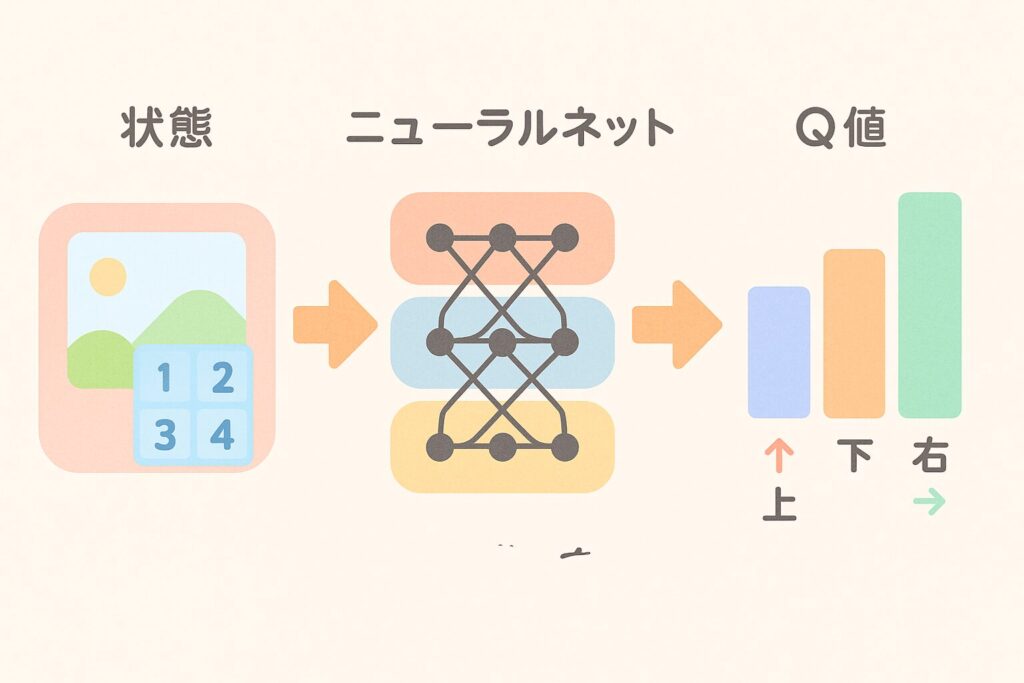
ニューラルネットを使うことで、巨大な状態空間でも対応できる ようになり、ゲームAI(Atari ゲームなど)や自動運転の研究で一気に注目されました。Q学習の“表更新”の感覚をそのまま深層学習に広げたものが DQN、と理解していただければOKです。
次の章では、この強化学習が実際の仕事でどう役立つのかを具体例で見ていきますね!
強化学習の実務応用:あなたの仕事ならどこに使える?
ここまでで強化学習の流れがつかめてきたと思いますが、「これって実際の仕事でどこに使えるの?」という疑問もありますよね。実は、強化学習は“試しながら最適な動きを探す”のが得意なので、リアルな業務にもけっこう使えるんです。
たとえば 在庫管理。コンビニや倉庫では「仕入れすぎてもダメ、少なすぎても売り切れる…」という調整が必要ですよね。強化学習なら、日ごとの売れ行きを見ながら“ちょうどいい量”を少しずつ学んでいけます。
広告配信でも活躍します。「どの広告を今出すと一番クリックされそうか?」をリアルタイムで学習して、ムダな広告費を減らせます。
工場のロボット制御なんかも相性抜群で、ロボットが“より速く・より失敗しにくく”動く方法を学んでいきます。
もしあなたがデータを扱う仕事なら、売上予測 → 最適なアクションを選ぶ という流れの部分に応用できる可能性が高いです。また、実務で強化学習を使うときは データの見える化ツール(例:Tableau・Power BI/1〜3万円程度) があると分析がとても楽になります。
次は、読者がつまずきやすいポイントを事前に解消していきますね!
よくあるつまずきQ&A:動かない/学習しない/迷走する原因
Q学習のコードは短いのに、実際に動かすと「え、なんで?」みたいな壁にぶつかることがよくあります。ここでは特に多い“初手でつまずくポイント”を、原因→対処でサクッとまとめておきますね。
Q1. 行動がずっとランダムで、全然学んでる感じがしません…?
原因:ε(イプシロン)が大きすぎて、ずっと探索モードになっているパターンです。
対処:epsilon = 0.1 くらいにしてみてください。0.01〜0.2 の間で調整すると安定しやすいです。
Q2. 報酬が全然入らなくて、Qテーブルが更新されません!
原因:環境の設定が合っていないか、そもそもゴールまで行けてない可能性があります。
対処:FrozenLake の場合は is_slippery=False にすると成功しやすくなります。まずは“クリアしやすい設定”で学習させるのがコツです。
Q3. 学習が暴れまくって、Q値がヘンな方向に行きます…
原因:学習率(lr)が高すぎて、毎回の更新がドカンと入りすぎていることが多いです。
対処:lr = 0.1 → 0.05 → 0.01 と少しずつ下げて試してみてください。
Q4. 行動が迷走してゴールできない…
原因:報酬の設計がシンプルすぎたり、逆に複雑すぎたりします。
対処:最初は 「ゴールで +1、落ち穴で −1」だけ の最低限でOK。慣れてきたら中間報酬を入れると賢くなります。
次はいよいよ、学習の“その先”を示すロードマップをまとめていきますね!
学習ロードマップ:この次に学ぶべきこと(DQN→Actor-Critic など)
ここまで読んでいただけたら、もう強化学習の“入り口”はばっちりクリアできています。Q学習を動かせた時点で、強化学習の考え方はしっかり身についているので、この先はゆっくりステップアップしていけば大丈夫です。
次の学習ステップとしては、まず DQN(深層学習 × Q学習) を触るのが自然です。その後は、より安定して学習できる Actor-Critic(A2C / A3C)、さらに発展版の PPO や SAC などに進むと、実務レベルのモデルも扱いやすくなります。






強化学習は一歩ずつ積み上げれば必ず伸びる分野なので、楽しみながら進めていただければ嬉しいです!
よくある質問
- Q強化学習って、そもそも何がすごいんですか?
- A
自分で試しながら学べるところがすごいです! 正解を教えなくても、自分で「うまくいく行動」を発見してくれます。
- QQ学習って数学できなくても大丈夫ですか?
- A
大丈夫です! 数式の部分は「テーブルを少しずつ更新する仕組み」と考えればOKです。
- QPython は初心者でも動かせますか?
- A
はい! この記事のコードは30行くらいなので、コピペでもちゃんと動きます。Google Colab ならインストールなしで使えます。
- Qどのパソコンでも強化学習ってできますか?
- A
軽いQ学習なら 普通のノートPC(5万円〜)で余裕 です。DQN以上になるとGPUがあると快適ですが、学習自体はできます。
- QQテーブルってどれくらい大きくなるんですか?
- A
状態数 × 行動数の大きさになります。迷路なら小さいけど、画像のゲームになるとテーブルが現実的に作れないくらい巨大になります。
- Q報酬ってどう決めたらいいんですか?
- A
最初はシンプルでOKです。「ゴールで +1」「失敗で −1」など最低限で問題ありません。複雑にしすぎると逆に学習が迷走します。
- Q学習がぜんぜん進まないのはなぜ?
- A
だいたい ε(探索率)が大きい / 学習率が高すぎる / 報酬が入りづらい のどれかです。パラメータをゆるめに調整してみてください。
- Qgymnasium のエラーが多くて困ります…
- A
gym と gymnasium が混在している可能性が高いです。
pip uninstall gym pip install gymnasiumを試すと直りやすいです。
- QDQN を学ぶ前に何を理解しておけばいい?
- A
Q学習の「状態・行動・報酬・更新」の流れが分かっていれば十分です。ニューラルネットの基本(層が増えると何が起きるか)も知っておくと楽です。
- Q仕事で使いたいけど、どこから始めればいい?
- A
まずは業務の中で “試行錯誤が必要な部分” を探すのがおすすめです。例:在庫量の調整、広告入札の最適化、ロボット動作の効率化などです。